
Our AI timeline
Thomson Reuters has been innovating for its customers from day one - which for some customer segments goes as far back as the 1800's. Initially, technology was used to collect, organize, and enhance information for its customers. Later, it would employ artificial intelligence (AI) to improve the customer's ability to find the information they needed. Today, we use AI to better understand our customers and surface information and insights they need when they need it. Thomson Reuters, through its different businesses, has had a formal applied research and development group since 1992.
Follow our AI @ Thomson Reuters timeline to discover our innovation journey.
Today
AI @ Thomson Reuters - We're Just Getting Started!
Today, Thomson Reuters is scaling innovation for its customers to new heights. How will AI transform our industries tomorrow? AI @ Thomson Reuters is working on that answer today!
2025
Risk Analysis Summary

Risk Analysis Summary is a new GenAI-powered tool designed to reduce the time it takes CLEAR users to investigate and conduct due diligence on businesses, corporations, and potential vendors. To simplify the decision-making process for CLEAR users, the Risk Analysis Summary report uses GenAI to produce a concise, easy-to-read summary of the key data points in any given company, all presented in a couple of pages, including links back to the original source documents.
Ready to Advise

The ‘Ready to Advise (R2A)’ project focuses on creating AI-enabled advisory capabilities for CPAs and tax advisors, such that they can seamlessly tailor strategies to meet clients’ unique needs.
By leveraging Agentic AI and automation, the product assists CPAs in creating a list of tax planning strategies based off of client tax returns, allows them to dive deeper into research with assistance of an AI powered chat and guides them through the different steps needed to implement tax strategies. The system includes an end-to-end guided agentic workflow for data extraction, strategy discovery, implementation and generation of client deliverables. Behind the scenes, Ready to Advise also supports the editorial tooling needed for strategy creation and refinement.
Knowledge Service – CoCo-TAAP

Enabled direct access to Checkpoint content within CoCo-TAAP by deploying a dedicated Search cluster and ETL workflow to ingest structured documents, vectors, and full-text HTML. This integration eliminates the need for scraping, ensures content is current and complete, and brings Checkpoint data fully into the CoCo-TAAP ecosystem to support more reliable and scalable search. This will remove dependency on the Checkpoint search API and transition to a modern, scalable search stack that supports experimentation and handles higher usage more effectively.
Disclosure Review - Automate

An AI-powered application that automates the validation of disclosures in financial statements and completion of financial disclosure checklists by analyzing financial statements and identifying disclosures made. Using Large Language Models, it populates checklist responses with traceable citations. A built-in human-in-the-loop system allows subject matter experts to review and refine AI-generated outputs, improving accuracy and compliance.
Westlaw Advantage Deep Research
Westlaw Advantage Deep Research is an agentic AI system that conducts legal research with the sophistication of a practicing attorney. Unlike traditional RAG tools that simply summarize search results, Deep Research plans multi-step research strategies, executes parallel searches across Westlaw's exclusive toolset, and adapts its approach based on new findings, just as experienced lawyers do. The system orchestrates specialized AI agents that use Westlaw content (including KeyCite, Key Numbers, and Precision Research classifications) to navigate complex legal questions. Built with a verification-first architecture aimed at transparency, the system provides inline citations and direct links to authoritative sources, enabling lawyers to quickly verify AI-generated insights while maintaining the trust and precision required for professional-grade legal work.
Westlaw Litigation Document Analyzer
Litigation Document Analyzer is an AI-enhanced system for analyzing litigation documents and making recommendations for how to improve or respond to them. The mischaracterizations tool evaluates statements and quotations for legal accuracy, using a multi-step prompt flow with a reasoning model to review cited cases and their contextual usage. It determines whether the statements, quotes, and surrounding context accurately represent the cited authority. The related arguments and defenses feature uses agentic processes that analyze the arguments made in litigation documents and then conduct research, recommending related arguments and defenses that can strengthen a position or raise new arguments.
2024
Practical Law Clause Finder
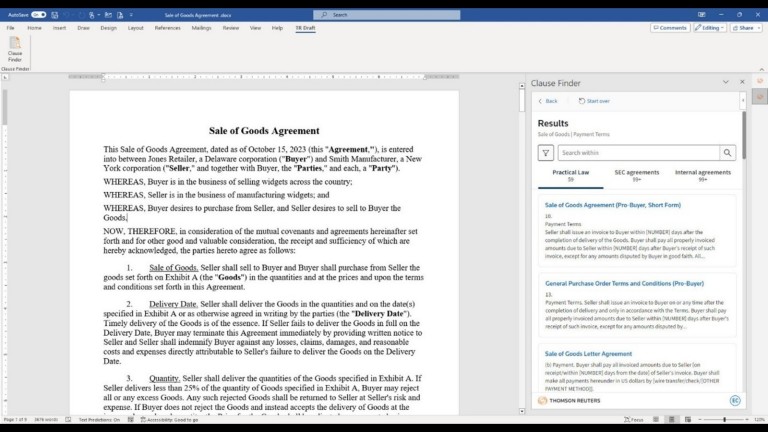
Practical Law Clause Finder is an AI-powered tool designed to streamline legal professionals' contract drafting and negotiation process by providing easy access to a vast database of Practical Law and other market-standard clauses at the point of drafting. It provides lawyers with AI-powered search to quickly find relevant precedent clauses without leaving Microsoft Word, leveraging Practical Law's trusted resources and editorial expertise and efficiently meeting the unique drafting needs of its users.
Ask Practical Law AI
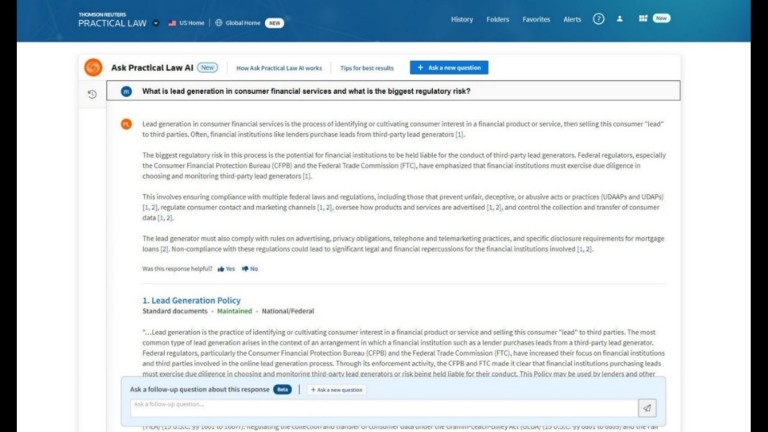
This is a generative AI system that uses Practical Law's robust search capabilities and comprehensive legal know-how content. Customers can ask questions using everyday language and get summarized, on-point answers with citations to trusted Practical Law resources.
Product Classification
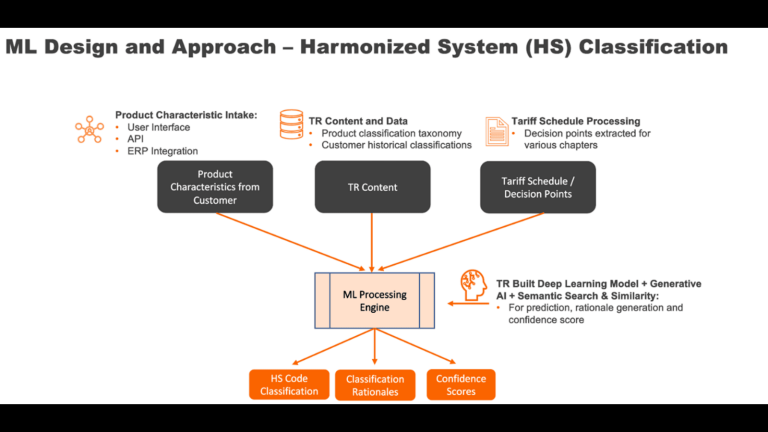
Cross-border and domestic transactions require accurate assignment of harmonized system (HS) codes so the authorities can apply the correct taxes and duties. As the World Customs Organization makes changes to classification codes and rules, it is crucial to review and revise the HS code assignments regularly.
Assigning the appropriate HS codes and keeping them accurate over time is a manual, time-consuming process that requires substantial subject matter expertise. Errors in HS code assignments may result in custom delays, overpaying, fines, or penalties due to incorrect product classification. Our state-of-the-art, AI-enabled classification capability is significantly more accurate and user friendly than the other solutions on the market, saving our customers hundreds of hours every month.
ONESOURCE Intelligent Assistant
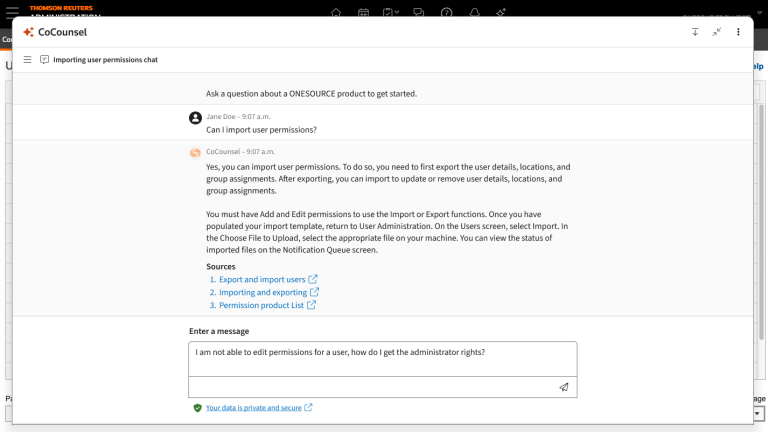
An AI-powered Product Support Assistant that transforms the way ONESOURCE customers access information by retrieving the most relevant information thereby making support interactions smoother. Customers can ask questions related to products and the AI assistant retrieves information from help/support content, provide links for details and auto-creates a ticket in case the customers need further help.
Audit Intelligence – Analyze
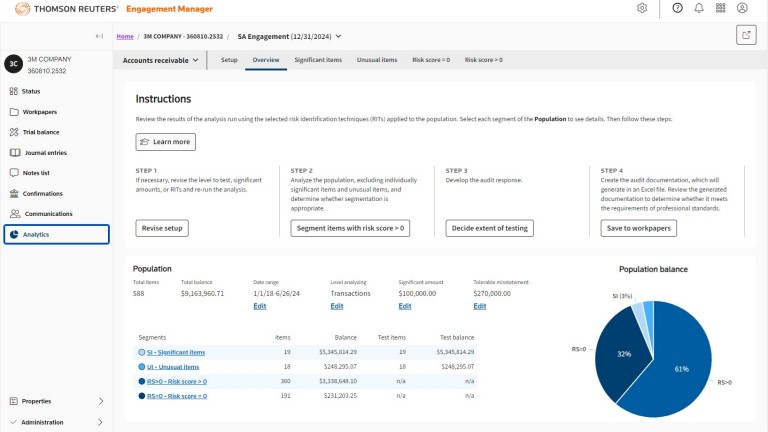
Our AI-driven solution analyzes each transaction in an audit client’s ledger system and assigns each a risk score. Auditors can then focus efforts on areas with higher potential risk of misstatement. The result—auditors are able to work more efficiently, in less time but with greater confidence.
2023
Westlaw Precision
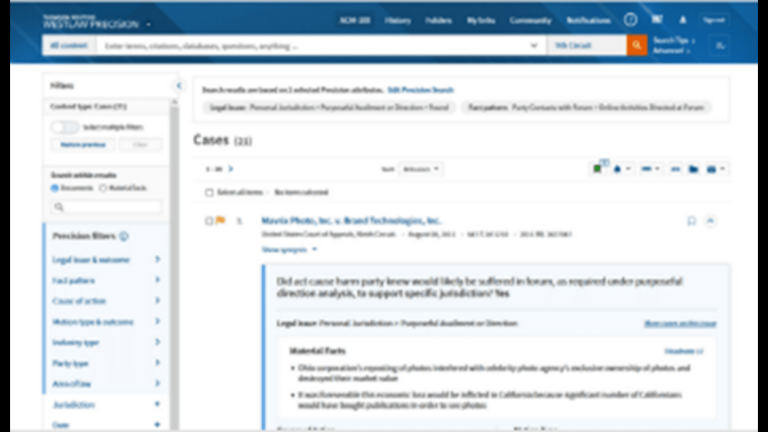
Thomson Reuters Labs developed a model to identify the most relevant headnote and Precision Research annotations from a case in response to a user’s query. It also delivered a new KeyCite Overruled in Part solution that identifies the specific point of law in a case that has been invalidated so that other valid points of law aren’t missed, using multiple models and leveraging editorial features with a new inference pipeline.
AI-Assisted Research on Westlaw Precision
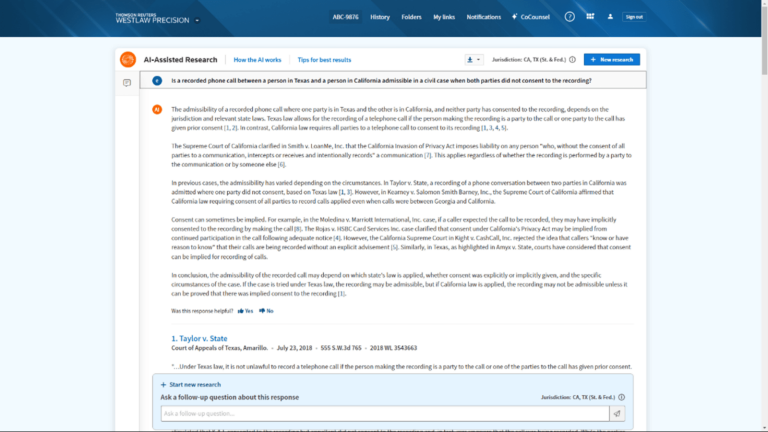
AI-Assisted Research on Westlaw Precision harnesses the power of generative AI — grounded in Westlaw’s trusted content — to quickly create new, relevant answers to legal professionals’ questions. This capability jumpstarts their research, helping customers complete it more efficiently and make more well-informed decisions.
CoCounsel Core

CoCounsel Core is a collection of AI capabilities that helps legal professionals complete critical tasks such as document review, database research, correspondence, and more.
2022
Document Intelligence
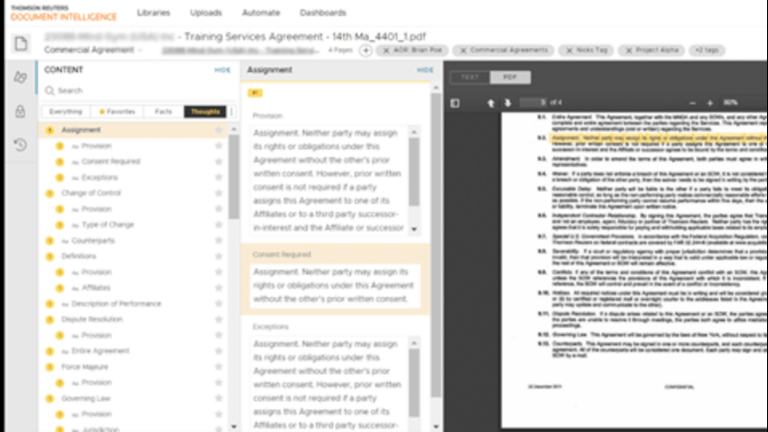
Document Intelligence uses pre-trained AI to identify crucial information within documents, enabling superior contract drafting and comprehensive research with unparalleled efficiency. By swiftly extracting insights and business intelligence from thousands of contracts within minutes, this solution transforms complex drafting and contract analysis work into manageable tasks, allowing legal teams to move faster and answer critical questions with precision.
Trained by Practical Law attorney-editors, the domain-specific AI models are designed specifically for various industries and legal practices, ensuring optimal performance and fast time to value. Document Intelligence empowers legal professionals to focus on providing strategic legal guidance and proactively identifying opportunities instead of drowning in the minutiae of document examination.
AI platform launched to support enterprise AI solutions

AI Platform launched in 2022 to facilitate time-to-market for data science and machine learning teams. Core to the team’s principles is the implementation of data and model governance standards and the operationalization of the model release process. This internal platform is built upon both existing and new tools, continuously reimagining them to support wider organizational needs.
Concluding 2022, the platform consisted of:
Data Service, AI Annotation, AI Workspaces, Model Registry, Model Deployment, Model and Data Drift Monitoring, Bias Monitoring
Updated Practical Law Dynamic Search
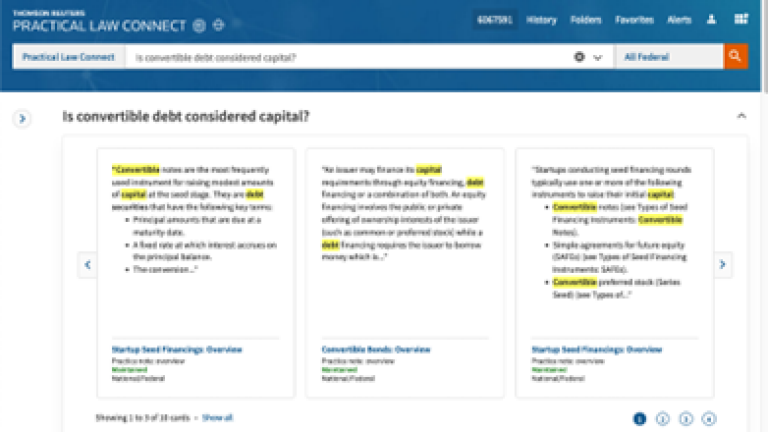
An updated version of PLDS was released that not only retrieves relevant answers more often, but nearly eliminates non-relevant answers from appearing in the top 5 results.
UK Grading
In its on-going effort to make editors and their workflows more efficient, Thomson Reuters is introducing greater amounts of Artificial Intelligence (AI) and Machine Learning (ML) into its production processes. A recent example is the UK Judicial Cases Editorial Treatment Process, which predicts the importance of an incoming case, based on properties like court name, subject area, keywords, and even level of anonymization required, if any.
The automated process leverages AI in order to queue the work for editors and to help ensure that the most important cases are processed first by our editorial team. State of the art ML operations have enabled this project to be successfully integrated into the associated production workflow and to deliver significant cost savings.
Legal Tracker Advanced
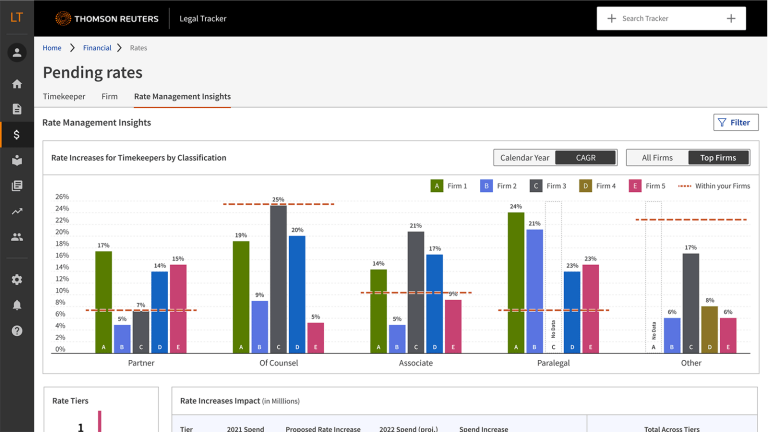
Legal Tracker Advanced brings the power of AI analytics and industry insights to empower law departments to strengthen spend management and operations. We delivered interactive data visualization for the Rate Increases dashboard in Legal Tracker Advanced, which facilitates users to make the data-driven decisions for allocating spending.
Thomson Reuters Labs at 30: Celebrating Three Decades of Innovation

At Thomson Reuters Labs, we are committed to driving progress and making a positive impact on the world. We are proud of the innovation we have delivered over the past 30 years, and we look forward to continuing to push the boundaries of what is possible in the next 30 and beyond.
2021
Released Practical Law Dynamic Search
State-of-the-art AI system designed to find the answers to free-form questions in Practical Law. It searches content-based on complex questions, as opposed to keyword queries, which poses unique and significant challenges. PLDS allows users to ask for exactly what they need without having to guess at a suitable keyword query.
2020
Legal Tracker
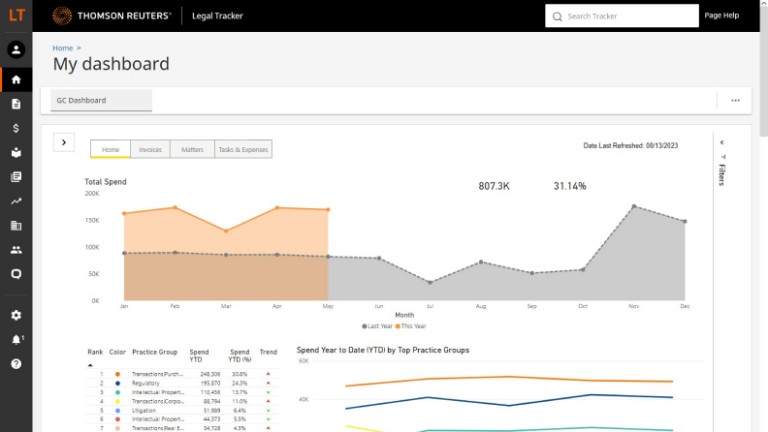
Our first partnership with the Legal Tracker team looked to enhance the capabilities of the invoice review process using AI technologies. Using machine learning classification techniques to predict if an invoice narrative violates specific billing guidelines, we launched a feature to detect block billing on invoices and invoice items describing non-reimbursable work such as travel, or internal communication.
2010
WestlawNext
WestlawNext
Building on all our previous experience, a wide array of AI technologies were leveraged to solve a wide set of challenges. It used machine learning (ML), clustering, classification, usage log analysis, citation network analysis, topic modeling, and natural language generation – the veritable "kitchen sink" of AI. The result was WestSearch. WestlawNext set a new standard for legal research solutions. AI enabled the system to go beyond traditional search.
2011
Reuters Insider
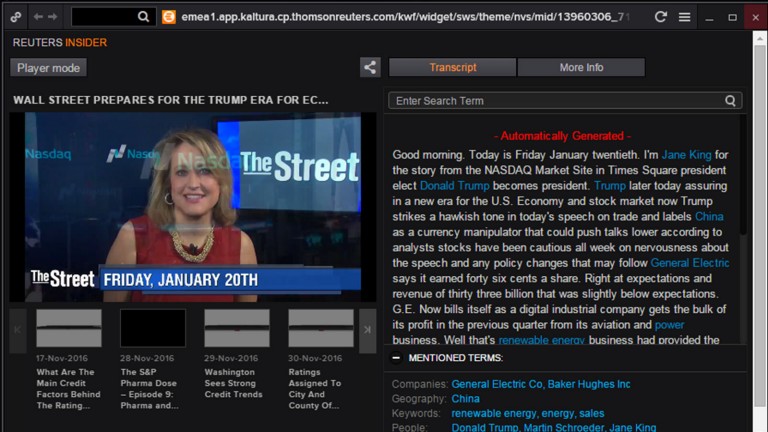
Reuters Insider
Reuters Insider used CaRE classification and Dexter entity extraction to connect transcripts of live news shows to video; this enabled searching video-based news.
NewsPlus
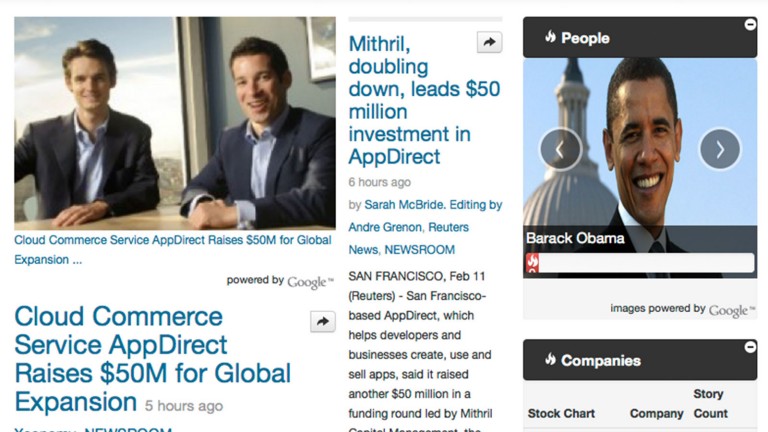
Screenshot showing how NewsPlus can drive an entire news portal - leveraging recommendation, deduplication, clustering, trending entities, summarization, etc.
NewsPlus is a content recommendation platform used in Westlaw and Eikon. The recommendation algorithms incorporated information from multiple sources to retrieve, filter, and prioritize news given the context of a specific user and application. It analyzes, de-duplicates, and groups/clusters the content. Like its predecessor, ResultsPlus, it used a hybrid approach of content and collaborative filtering.
2013
Checkpoint - Broadside
Checkpoint Broadside applied many of the technologies and approaches used in WestlawNext to power the new "Intuitive Search" capability in Checkpoint, our market-leading research solution for tax and accounting professionals.
Magnet
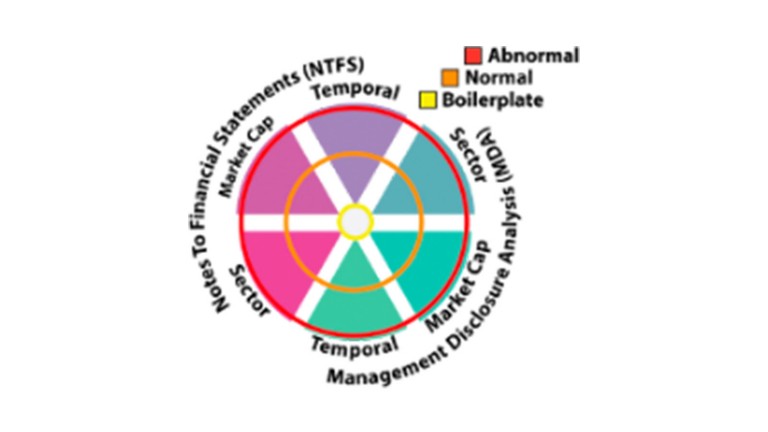
Magnet provided an indicator for boilerplate, normal, or abnormal language along 3 dimensions in two key parts of SEC filing documents
Magnet analyzed SEC filing for deviation in language that may merit further review. An analysts could then review and provide deeper insights into related plans, initiatives, prospects and challenges; in effect, expanding the news coverage of that company.
2015
Reuters Tracer and Social Data Platform (SDP)

Separating Real News from Fake in 40 Milliseconds
A platform and tool created for Reuters journalists to monitor Twitter for breaking events. Tracer filters out social media noise and identifies potential breaking news events. It utilized natural language processing (NLP), content classification, clustering and machine learning. A special Tracer feed is provided to Eikon as a completely automated real-time news feed.
2018
DPA - Data Privacy Advisor
Data Privacy Advisor
Data Privacy Advisor incorporates a next-generation question-answering feature built in partnership with the Thomson Reuters and IBM Watson.
Adverse Media
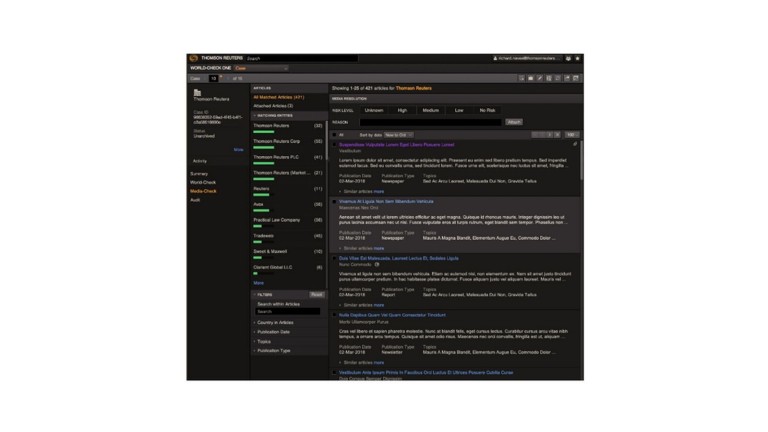
Adverse Media
Adverse media capabilities enable our analysts to perform adverse media screening from tens of thousands of news sources. In addition to extracting risk signals, these capabilities also perform concordance from unstructured sources. This capability helps analysts in performing ongoing background checks that support Anti-Money Laundering regulations. In particular, this new capability will perform interactive person name disambiguation and identify text/documents that potentially contain evidence of financial crimes. This service was being done manually by analysts. The solution searches news articles and leverages NewsPlus tagging capabilities. This capability is used in World-Check One: Media Check.
AutoMuni - Automated Municipal Bond Pricing
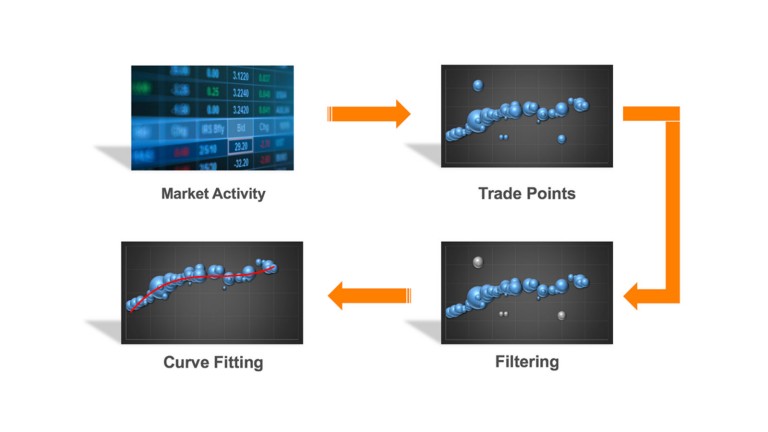
AutoMuni
The accurate evaluation of approximately a million bonds daily is a big challenge. The muni valuation method is quite manual. Such an approach is not only time consuming and costly, but also only a small portion of bonds can be accurately evaluated due to the restriction of resources. The AutoMuni system helps scale the valuation process by using intelligent, machine learning, algorithms that can price the entire fixed income universe automatically and efficiently.
Inferno
Inferno
Inferno is a data ingestion and workflow tool to help analysts refresh content within the World-Check database. This helps to improve the accuracy and reliability of World-Check which is crucial in keeping the competitive advantage. It mines news feeds and then uses various techniques, including machine learning and natural language processing (NLP), to enhance the data ingestion workflow, increasing the speed and accuracy of identifying required updates to World-Check data.
Westlaw Edge: WestSearch Plus
WestSearch Plus on Westlaw Edge
WestSearch Plus answers customers' questions posed in natural language. Behind the scenes, it mines the rich analytical material in our headnotes as the source for answers. It uses editorial guidelines to divide Headnotes into frames/intents. Then it classifies both answers and questions (mined from the query logs) to those intents. WestSearch Plus uses search strategies based on questions and intents to assemble a headnote candidate pool and uses natural language processing (NLP) & discourse features in XGBoost model to classify/score answers.
Westlaw Edge: Litigation Analytics

Litigation Analytics on Westlaw Edge
Lawyers now have all the analytics from past cases at their fingertips and can shape their litigation strategy with Westlaw Edge's Litigation Analytics.
Many AI methods were used including deep learning. It extracts information from federal dockets, identifying names and relationships of all parties. It identifies case topics and adds all this information to a knowledge graph. The knowledge graph is continually updated. Customers use natural language to explore this knowledge graph. When returning results, the AI generates text narratives explaining the generated visualizations.
Westlaw Edge: KeyCite Overruling Risk
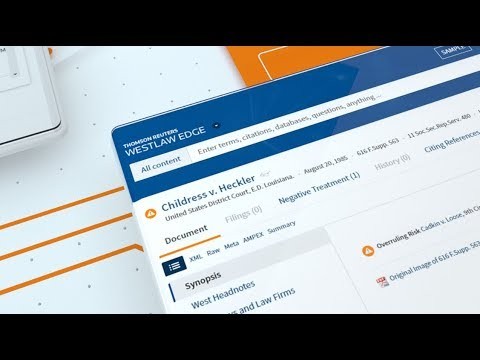
KeyCite Overruling Risk on Westlaw Edge
KeyCite is our market leading case citator system. It is important to identify cases that are negatively impacted by an overruling decision, and to flag them as possibly impliedly overruled cases that need further careful examination. The AI-powered solution identifies those cases using machine learning algorithms.
The problem is formulated as a binary classification of candidate cases into those that are negatively impacted (and possibly impliedly overruled) and those that are not (and hence are still safe to be relied on in a legal investigation). Our classifier uses a variety of features, including metadata information about the cases, citation paragraphs in the overruling and affected cases, as well as headnotes in the overruled case.
2019
Deep Learning Center Launched in Boston

Deep Learning at Thomson Reuters
Thomson Reuters launched a deep learning center in the heart of Boston, Massachusetts, very appropriately addressed at 1 Thomson Place. This marked a growing commitment within the organization to expand capabilities across core technology domains. Deep learning methodologies can greatly add to the proficiency of related fields like natural language processing or image processing and analysis. The implications of this field are substantial across operational efficiencies as well as discovering new insights across key industry segments.
Checkpoint Edge
Checkpoint Edge introduced an entirely new feature called Concept Markers and made further enhancements to the Intuitive Search algorithms that assist and guide the research process. It helps users refine and/or elaborate on their queries to find answers. Natural language processing (NLP) and machine learning (ML) technologies were used to enable these features.
Westlaw Edge : Quick Check

Westlaw Edge Quick Check™ In the Making
Attorneys perform hours of legal research so that they can provide their clients with the best possible representation. They are under constant pressure to do their best work as efficiently as possible.
Quick Check is a Westlaw Edge feature that, given a legal document, finds additional supporting authority to research. This helps our customers complete their legal research faster and have a higher degree of confidence in their work. It also enables them to do a thorough analysis on their opponent’s work and in turn help them be more prepared for their clients.
2000
PeopleCite & Profiler
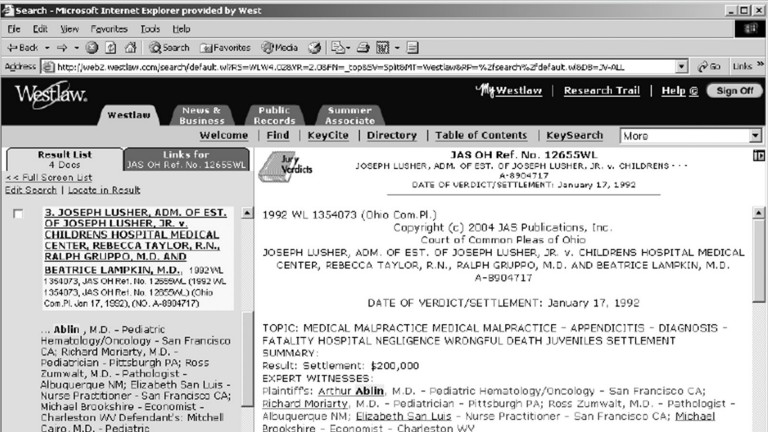
Jury Verdict and Settlement Document with Hyper Links to Attorneys, Judges, and Expert Witnesses including Arthur Ablin
PeopleCite and Profiler extracted entities from American case law documents to create a knowledge base of judges, attorneys, and expert witnesses with links to all their cases and biographies. Machine learning enabled those systems to analyze millions of documents, a scale far beyond what could be done manually. [Info Today]
2001
CaRE - Classification and Recommendation Engine
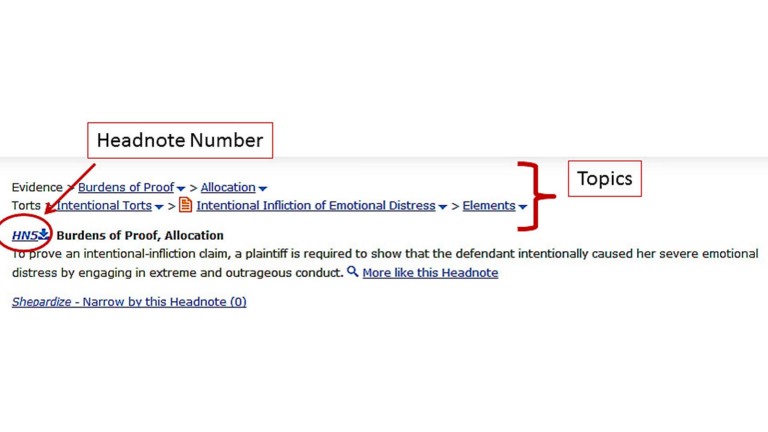
Headnotes are summaries of the issues in a case. Headnotes in West reporters are written by the editors.
Using an ensemble of machine learning algorithms, CaRE has been used widely across the company to classify legal, tax and finance documents to large taxonomies, e.g., CaRE is used to classify millions of headnotes to a KeyNumber taxonomy with more than 90,000 categories. CaRE later formed the basis of ResultsPlus (2003) - a very successful document recommendation system. It is still in use today (2019).
2003
ResultsPlus
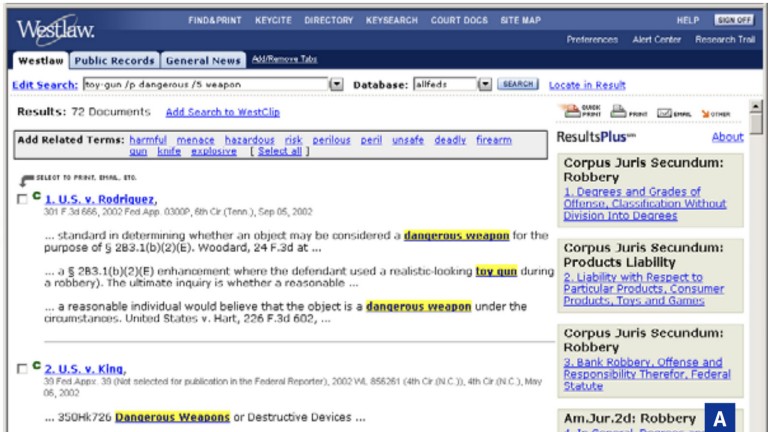
ResultsPlus
ResultsPlus was a very popular document recommendation solution in Westlaw. Based in part on CaRE, the system made contextually relevant recommendations of secondary law documents, Key Numbers, briefs and more alongside search results. The system incorporated: natural language generation of summaries for briefs; user behavior analysis to enable personalized recommendations; and dynamic ranking of selections based on data from real-time A/B testing.
2005
Firm360
Firm360
Built on the work done for the Profiler project to link attorney and judge names, this system identified law firms and companies, and used semantic parsing and discourse analysis techniques to infer the relationships among judges, attorneys, law firms, their roles, and the companies they represent. The metadata was stored in a data warehouse which in turn fed the Firm360 reports.
2006
Dexter

Dexter
Dexter is a machine learning (ML)-based named entity extraction and resolution (NER)system focusing on news and legal content. It is used in many products including Reuters Insider (2011).
2007
Medical Litigator
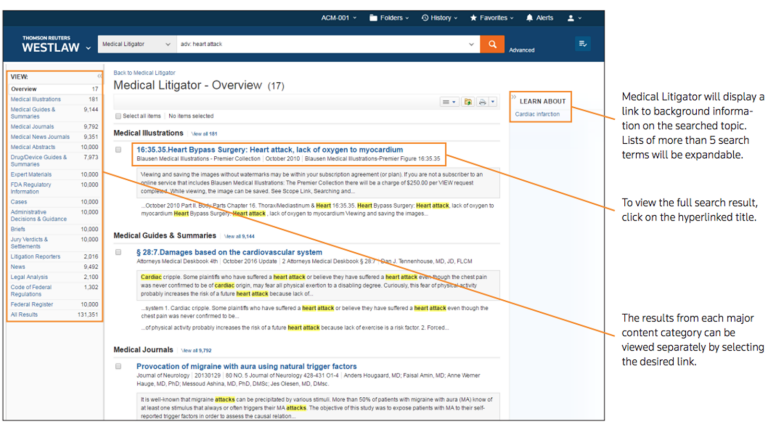
Medical Litigator
Westlaw Medical Litigator provided legal researchers with immediate, "one-stop" access to information about medical terms, procedures and devices related to medical malpractice, personal injury, and device liability. In addition, it provided an understanding of related medical issues, health care professionals and expert witnesses. It included natural language support and disambiguation tagging.
2008
Concord
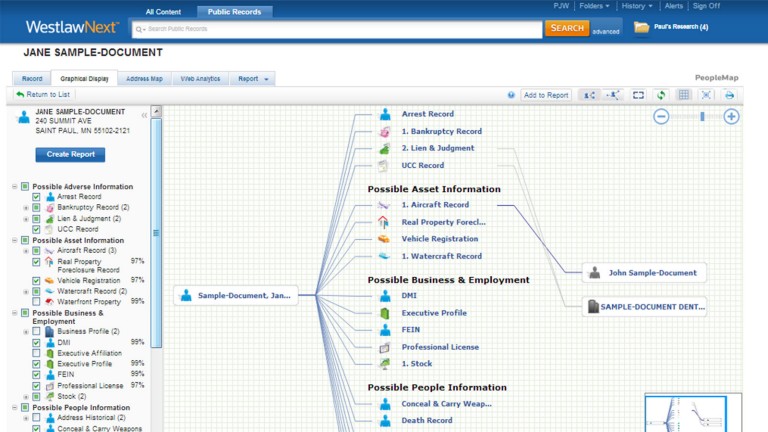
In the market intelligence domain, Concord and Dexter were used to extract entities and resolve such mentions to authorities to create the litigation history database behind West's Litigation Monitor.
Thomson Reuters provides one of the largest and most diverse set of Public Records in the United States. Concord enables searches where there could be thousands of "John Smith"s, connecting the correct records among hundreds of millions of records, and many more possible connections. It was, perhaps, the first statistics-based record linking and resolution solution of this scope in the public records domain.
1991
Scientist Spotlight: Howard Turtle

Howard Turtle
As chief scientist, Howard Turtle helped found one of the first R&D groups at Thomson Reuters. He is a nationally known scholar in search engine technologies, having developed a formal retrieval model based on Bayesian Inference Networks that formed the basis of the University of Massachusetts’ INQUERY Retrieval System and of West Publishing’s natural language search product, called WIN. Howard led the legal R&D group until 1996. Howard Turtle retired from Syracuse University in 2016.
1992
WIN (Westlaw is Natural)

Researching on a Westlaw terminal, with a sign for “WIN: Westlaw Is Natural" that says "Try the only legal research service that lets you search in plain English!" Irvine, 1993.
Westlaw Is Natural (WIN) was the first commercially available search engine with probabilistic rank retrieval. Howard Turtle led the effort after completing his PhD at UMass. This was an innovation milestone for legal research because prior to that most search engines only supported Boolean term & connectors.
1995
Scientist Spotlight: Peter Jackson

Peter Jackson
Peter Jackson was one of the founders of research and development (R&D) at Thomson Reuters. Peter joined Lawyers Cooperative Publishing (LCP) and formed the natural language processing (NLP) group in 1995. In 1998, Peter assumed leadership of the legal R&D group. Peter became Chief Research Scientist & Vice-President, Technology in 2005 at Thomson.
1996
History Assistant

History Assistant
History Assistant was a large scale natural language processing (NLP) system that analyzed case law documents, extracted parties, judges and built the appellate chain for a particular case. The system found history relationships between court decisions by using a combination of information retrieval and machine learning techniques to link each new case to related documents that it may impact.
1975
Westlaw

In 1986, the Harris County Law Library began offering Westlaw as part of its collection through a terminal named WALT - a.k.a. West Automated Legal Terminal - similar to the one pictured here.
Westlaw was one of the first online legal research services. Attorneys used dumb terminals to dial up to a mainframe. The content was limited (disk space was expensive) and the search language simplistic.
Westlaw marked the beginnings of technology-driven innovation in many ways for legal sector.
AI @ Thomson Reuters
Thomson Reuters and Generative AI: Defining a new era for how legal and tax professionals work