
As agentic AI and regulatory demands accelerate, organizations must reinvent their data core with an adaptable data foundry to ensure scalable, explainable, and compliant AI-driven outcomes
Key takeaways:
-
-
-
There is a widening gap between AI ambition and readiness — The gap between AI ambition and data readiness is widening, making the adoption of an adaptable data foundry essential for scalable, explainable, and compliant AI outcomes.
-
A data foundry model directly addresses the root cause — A data foundry model enables organizations to industrialize data production, automate compliance, and ensure consistent data lineage, thereby overcoming the limitations of brittle, legacy data architectures.
-
Incorporate the data core into your AI planning — Reinventing the data core is now a strategic imperative for those enterprises that aim to thrive in 2026 and beyond, as agentic AI, regulatory demands, and integration complexity accelerate.
-
-
This article is the third and final installment in a 3-part blog series exploring how organizations can reset and empower their data core.
A defining theme of this year so far is the widening distance between organizational ambition and data readiness. Leaders want the hype and inherent capabilities they believe are instantly contained within agentic AI — automated compliance, predictive integration for M&A, and decision-intelligence pipelines that reduce operational friction.
Without a data foundry, however, much of that will be impossible. Instead, workflows will remain brittle, AI agents will hallucinate under inconsistent semantics, and data lineage will break down across federated sources. Further, without a data foundry, regulatory mappings involved with the Financial Data Transparency Act (FDTA) and the Standard Business Reporting (SBR) framework cannot be automated, cross-functional insights will require manual reconciliation, and auditability will collapse under scrutiny.
This is not a failure of leadership. It is a failure of architectural design to recognize the congealment of data as a predecessor to technologies and the critical priorities of data security, auditability, and lineage.
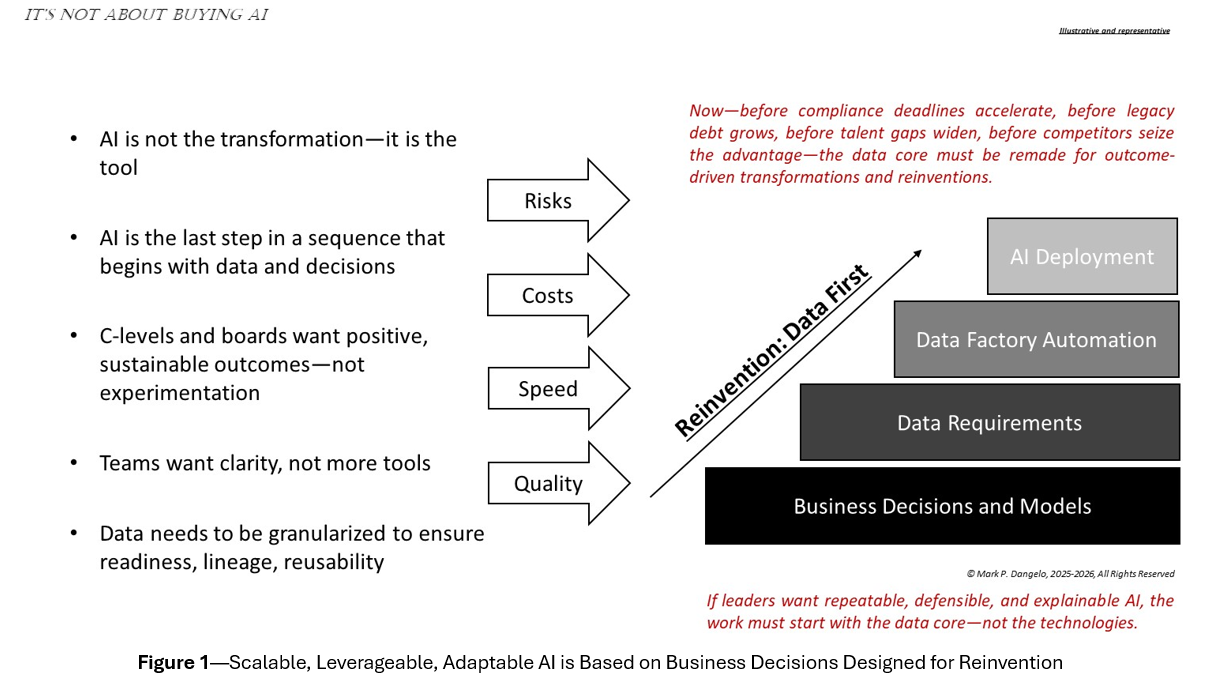
For decades, organizations built monolithic systems that were optimized for stability and reporting. Today’s world demands modularity, continuous adaptation, and agent-driven interoperability. Architecture has shifted from build and operate to build and evolve. This is precisely what a data foundry enables.
Why reinvention can no longer wait
Throughout 2025 and now into the early months of 2026, data and AI have quietly shifted from innovation topics to enterprise constraints. Leaders across regulated markets are starting to recognize that the obstacles limiting their AI ambitions are neither mysterious nor technical — they are structural. These obstacles sit inside the data core, waiting inside the silent architecture that determines whether any form of automation, intelligence, or compliance can scale beyond a pilot.
The data bears this out. When you examine the work coming from Tier-1 research bodies, supervisory institutions, and global transformation benchmarks, a consistent narrative emerges beneath the headlines: AI is accelerating, regulation is hardening, and integration demands are expanding. Moreover, organizational data remains pinned to assumptions that were forged in static, pre-AI operating environments. This gap is not theoretical; rather, it is measurable, persistent, and directly correlated to business performance.
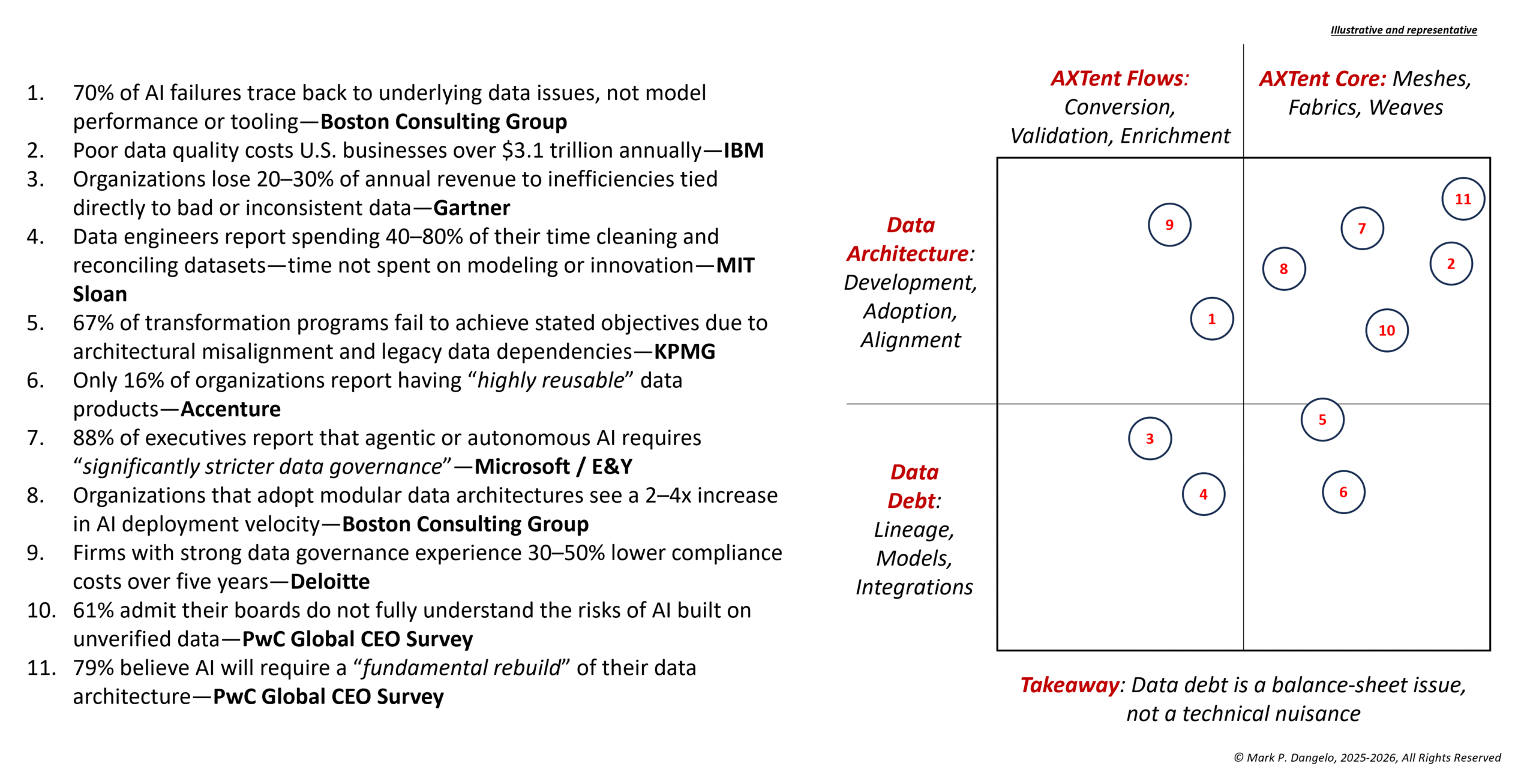
Let’s look at the AI results first. Across industries, organizations continue to experience a familiar pattern: early promise, limited adoption, and rapid degradation once the model encounters inconsistent semantics or fragmented lineage. Global studies show that the vast majority of enterprise AI initiatives still struggle to reach full production maturity, and among those that do, many encounter performance drift within the first year.
The driver is remarkably consistent. It is not the sophistication of the model nor the skill of the data science team — it is the quality, clarity, and traceability of the data that is feeding the system.
Taken together, these signals deliver a clear message. The gap between AI ambition and data readiness is widening, not narrowing. This is why the data foundry conversation matters now. It is not an abstract architectural concept. It is a response to the full stack of quantitative pressures the market has been telegraphing for years — costs rising, compliance hardening, AI accelerating, and integration straining under inconsistent semantics and fragile lineage.
A data foundry model directly addresses the root cause of this by industrializing the creation of consistent, reusable, explainable data products that can fuel agentic AI, support regulatory defensibility, and accelerate enterprise reinvention.
The numbers point to a simple conclusion. Reinvention is no longer optional, and the window to address the data core before agentic AI becomes standard practice is narrow and closing. The organizations that act now will be the ones that define what compliant, explainable, interoperable AI looks like in the next decade. Those that defer the work will find themselves restructuring under pressure rather than reinventing by choice.
This is the inflection point. In truth, the quantitative signals have made the case more clearly than a multitude of strategy narratives ever could.
The data foundry: A model for continuous alignment
Unsurprisingly, agentic AI introduces new, more demanding requirements, including:
-
-
- machine-interpretable semantics;
- context-preserving lineage across federated systems;
- decomposition of enterprise knowledge into reusable data products;
- dynamic trust-scoring tied to source reliability and timeliness;
- automated compliance overlays and regulatory logic; and
- cross-domain metadata orchestration.
-
These capabilities are not optional, and they are non-negotiable. Indeed, they determine whether AI elevates risk or mitigates it, whether it accelerates productivity or introduces unrecoverable inconsistencies. And they determine whether AI augments decision quality or produces volatility.
A data foundry shifts organizations from artisanal, one-off data preparation and toward industrialized data production, in which patterns replace pipelines, and building blocks replace custom engineering. This shift will mean that lineage is generated, not documented; semantics are governed, not patched; and compliance is automated, not reconstructed. In this way, reuse becomes the default, not the exception.
In fact, this process is analogous to manufacturing. Instead of producing bespoke components for each need, the enterprise creates standardized, high-fidelity data assets that can be assembled into any workflow, any AI use case, and any reporting requirement.
A data foundry becomes the quiet architecture behind every future capability, making these capabilities systematic rather than ad-hoc. The chart below showcases the progressive build-up using a data factory, beginning with data intake and harmonization and ending with the AI agent orchestration and reusable data products that learn from their deployment.
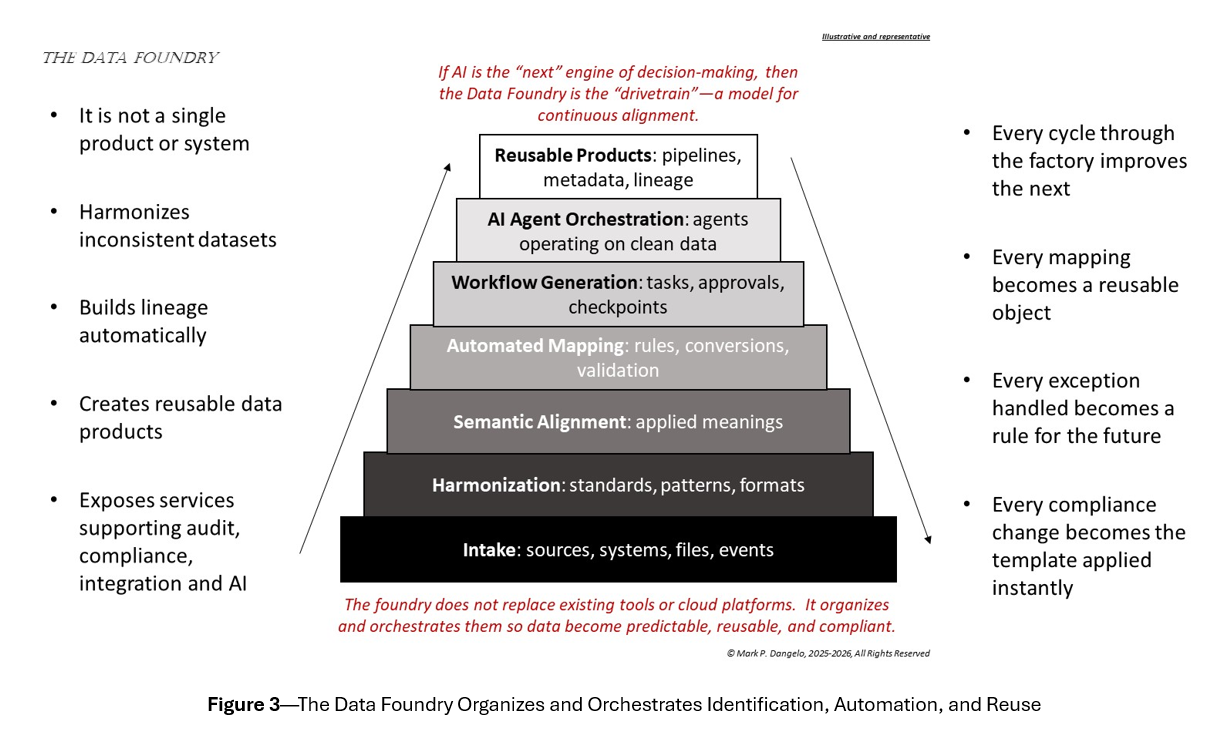
Unfortunately, organizations are still building increasingly advanced AI decisioning and efficiency solutions on top of an aging and brittle data foundation. The results are predictable: stalled initiatives, compliance exposure, and stakeholder frustration. Additionally, instead of asking why, organizations keep adding more tools — more dashboards, more cloud services, more AI pilots, and more flavors of transformation.
Clearly, enterprises aren’t dealing with an AI problem. They’re dealing with a data alignment problem disguised as progress within fragmented, AI enclosures.
Reinvention starts at the data core
For more than a decade, firms across regulated industries have repeated the same mantra: Data is our most critical asset. When you peel back the layers or when you sit in board review sessions or integration meetings or regulatory remediation audits, however, the evidence does not match the rhetoric.
Reinvention is no longer optional. Instead, it is the starting point for meeting the demands of 2026 and beyond. The institutions that thrive will be those that understand that the data core is not a technical asset — it is the operational backbone of the enterprise. Indeed, the institutions that succeed will be those that recognize the truth early: AI is an output, and the data core is the strategy. And the organizations able to industrialize their data — through a foundry model, through AXTent, through repeatable semantic structures — will be the ones leading innovation, reducing compliance risk, accelerating M&A synergies, and achieving enterprise-wide reinvention.
In the end, the real question isn’t whether AI will transform business; the question is whether the data foundation will allow it. And the answer is rebuilding your data core so AI can actually deliver the outcomes your organization needs — and that work begins now.
You can find more blog posts by this author here






